The TryHackMe machine Hammer contains a poorly implemented password recovery feature that can be exploited to gain a foothold on the system. Here I'll share how to hack into the first part of the challenge, what makes it possible, and how to prevent attacks like this in your systems.
Note
This is not intended to be a write-up for this challenge. Therefore, there are many places you will need to fill in the spaces.
Enumeration
After the initial enumeration of ports, we get to a webapp in port 1337, with a login page with a Forgot your password? link in it.
With a little more enumeration, we find some logs that have some interesting data, like the possible existence of a user with email tester@hammer.thm. This is confirmed with the password recovery form:
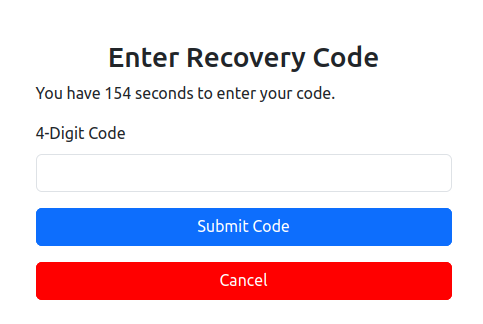
They are asking for a 4-digit code to reset the password, and as you can see from the screenshot, the page has a countdown; this is the (formatted) code for it:
.jslet countdownv = 180;
The page gives you 3 minutes to input the code before redirecting you to the logout page. Of course, this gives no security at all, as one can very easily modify the countdownv variable in the console or clear the interval set to update the count.
As I started trying values by hand, after a few requests, I got blocked and couldn't make any requests. I noticed that the blocking was tied to the value of the PHPSESSID, after removing it, the blockade was lifted.
The request set the header Rate-Limit-Pending: 9, which started with a value of 9 and decreased by one every time a request was made with the same session ID. When the value got to 1, I'd get blocked on the following request.
This means that I can try up to 9 different code values before I need to update to a new session ID and start over. Maybe I can do a brute-force attack.
Some math
Before starting to dump more carbon dioxide into the atmosphere with our inherently inefficient brute-force attack, it's worth asking ourselves if this makes sense. Is it possible to find the code within a reasonable time? To answer that, we need to answer another question: How many times on average should I try to guess the code before I succeed?
I'll take some time here to derive some formulas for probabilities to answer this question.
Probabilities
First of all, let's assume that the generated code is picked at random with a uniform probability distribution from to . This means, there's a probability (with ) that any of the possible 4-digit numbers is the code we are looking for.
If, given that the code is picked and fixed, we guess it is any 4-digit number, the probability that we are right is . If we now try again with another number, the probability of getting it right is, again, .
Important
It is fundamental that we are clear about this. Every guess is an independent event, and they do not affect the probabilities of each other.
Of course, the probability of having guessed the code after two tries is greater than the probability of having guessed it in only one try. But beware of the distinction between "the probability of having guessed after two tries" and "the probability of guessing in the second try". This may be a subtle distinction for people unfamiliar with probability, and is the source of many misunderstandings.
Here are two properties of the probabilities of independent events that will be helpful in the following:
Given two independent events and , with probabilities and respectively;
- the probability of any of the two happening is equal to the sum of the probabilities .
- The probability of the two events happening is equal to the product of the probabilities
With that in mind, let's break down the probability of guessing the code within two tries. There are two ways in which we could have guessed the code: in the first try and in the second try, and the probability of guessing in any of the two is the sum of those.
The first probability is easy, it's just . The second one needs a little more attention. We will be smart when guessing, so we will not choose the same number twice; then, the independent probability of guessing correctly the second time will be .
Now, for the correct guess to be the second one, two conditions must be met: we must not have guessed correctly in the first try, and we must guess correctly in the second one. So, the probability of this is the multiplication of the probabilities of the two conditions1:
With this, we get that the probability of having guessed the code after two tries is . This result can be generalized, and the probability of having guessed the code after tries is
Notice the notation. I'm using as a way to express that this is the probability of guessing correctly in any of tries, and that
where is the probability that the correct guess happens in the -th try.
Important
I can't stress this enough. Notice the distinction between "guessing in the -th try" and "the correct guess happens in the -th try". The former refers to a single event, whereas the latter involves multiple events.2
Notice that the probability can't be greater than , so if , the probability is , i.e., we are certain that we guessed the code because we tried every possible number.
More probabilities
Note
I will be reusing the variables , , and . Threat this section and the previous as independent scopes. Sorry for the confusion it might create.
Back to our problem, we know3 we have tries to guess the code before we are blocked. After that, we need to start over, because a new code is generated. We can group our guesses in batches of each, where the probability of guessing the code in a batch is . These batches are independent of each other if we keep our assumption that a random code is generated each time.
So, what's the probability of having guessed the code after batches? This is more easily calculated as the opposite of not having guessed the code after batches:
Let's break that down: the probability of guessing in a batch is , then the probability of not guessing is ; not guessing after batches requires not having guessed in any of the batches, so the probability is the product of the independent probabilities: . Finally, the probability of guessing in any of the batches is the complement of the previous, hence the equation above.
This is not to be confused with the probability of guessing in the -th batch. As before, these are independent events, so the probability remains . Also, not to be confused with the probability that the correct guess happens in the -th batch, this probability is the product of the probability of guessing in the -th batch and the probability of not having guessed until then:
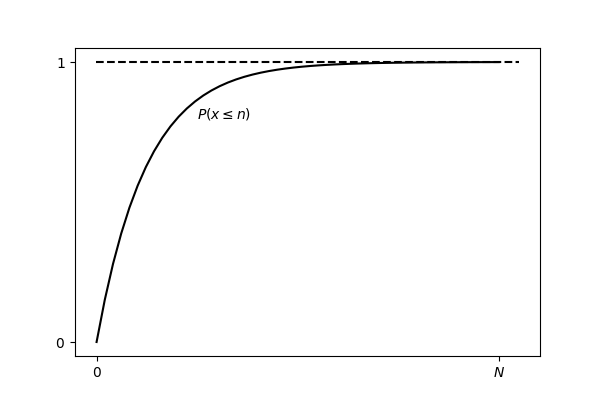
Below is shown the graph of . It approaches asymptotically but never reaches it. So, what was the point of all of this? The probability on its own is not very useful; we need another number: the expected value of the number of batches that need to be tried before guessing correctly.
Expected value
The expected value of a random variable is a weighted average of the values the variable can take, where the weights are the probabilities of each value.
As the name suggests, it gives a sense of what value one should expect when obtaining a random value of . In our problem, we are interested in the expected value of the number of batches to try for us to have a correct guess of the code:
This is the weighted sum of with the probability that the code is guessed in the -th try. Using the equations from above, the expression becomes:
To get the result, let's derive the value of the summation
Click here to see the derivation
We have the partial sum
Multiplying each side by we get
Then we can make the substitution , which lets us with
Let's solve the summation in the equation above:
With this result, our original summation becomes
Finally, applying the limit when , and because :
Subtituting for our problem we get
Let's interpret this result. If we substitute we get
batches. But in each batch we try times, so the expected number of individual attempts is .
This result seems very intuitive. In fact, this was my first guess long before even considering deriving the probabilities and expected value. What this result tells us is that, on average, if the code is a random number chosen each time from possible values, we should try to guess it times before getting it right.
Don't confuse this with the situation of a fixed code and guesses. In that situation, we are guaranteed to be right in the -th guess or before, then the expected value would be less than .
Exploitation
Note that in the previous interpretation of the result, the number of requests per batch gets cancelled out, so, in theory, it's irrelevant how many attempts per PHPSESSID we make. However, each attempt requires a request to be made to the website, and for each session ID, a new request needs to be made to get it. So, we should use the 9 requests allowed by each PHPSESSID if we want to take the least time to crack the code.
From the result, we also get that we will need, on average, 10000 attempts. If we made all the requests sequentially, and if every one of them took 100 ms, we would spend ~17 minutes until we cracked the code. In my experience with the machine, the requests took more than 100 ms each, so this approach is not desirable.
To speed this up, we can make concurrent requests to the server, therefore multiplying the attack speed. In crack.py, you can see the code I made to crack the pin. I used aiohttp instead of requests to make the requests concurrent. This is only one of many possible approaches; I could have made concurrent sessions as well to speed up the attack even more, but this was good enough to run within 20 seconds.
Also, notice that I used 8 requests per session instead of 9, because I need the potentially last request to fill the password reset form.
Preventing this attack
This application had three vulnerabilities that allowed us to exploit it. Let's see them and discuss how to prevent them.
Public logs
First of all, we were able to see logs of the system unauthenticated and without any authorization. The logs may contain sensitive information, like usernames, emails, or even passwords. So, make sure that your logs are not accessible to the public.
Verbose notifications
The next piece to get the email we used was exploiting the information given in the Forgot Password form. When the email entered was not in the database, there was an error message that told us. This can be used to check if an email is registered on the website, enumerating from a wordlist. In our case, we were able to validate that the email found in the public logs was registered on the website.
The takeaway of this story is to be careful about the information you give back to the user; it might seem harmless, but give away enough information for hackers to use.
Flawed recovery verification
Finally, using a 4-digit code to verify the authenticity of a password reset is not strong enough. As we saw, the expected number of attempts is only , and brute-forcing it is feasible. By adding only two more digits and including letters in the code, the time of the attack increases by more than 256,000 times. That's almost 3000 years with the same speed of tries per second.
Always make these calculations before implementing your authentication. The security of the Internet relies on brute-force to take astronomically large times when no information is given.
Also, blocking based on the PHPSESSID is not robust enough, as we saw, we can simply get a new one. Blocking or throttling by IP address would be a better approach to prevent brute-force attacks.
The probability of an event not happening is , where is the probability of the event happening.
I apologize if my writing makes these subtle differences even more difficult to distinguish.
Actually, we don't know this. We assume that a single code is generated for every PHPSESSID, and we can try many times to guess the same code until we get blocked.